[정보처리기사] 2025 정처기 필기 총정리 및 공부법
- 2025 정처기 1회차 합격 후기 및 공부법(2025.03.01 합격)
전공자임, 하루 10시간 5일 컷. 점수 84점.
이론서 안봄, 기출만 풀어도 충분함.
여전히 기출딸로 충분히 커버 가능한 수준.
- TBC 최강 자격증 기출문제 2020년 06월 06일 ~ 2022년 04월 24일 (8회분) 2회독.
- 이기적 복원 문제 2024년 1회차, 2회차, 3회차 1회독.
1. TBC 8회분 1회차, 정답 열어놓고 읽기.
2. TBC 8회분 2회차, 정답 열어놓고 읽기. 외울양 많은 파트는 따로 필기 해둠. ex) 정렬 알고리즘.
3. 이기적 복원 문제 2024년 1, 2, 3회차 풀기
총 5일 동안 19회독을 했다.
비전공자는 DB, 코딩, 정렬 알고리즘 개념만 확실히 익히면 나머지는 암기라 상관 없을 듯.
개념 이해 안가면 chatGPT한테 설명해 달라고하면 됨.

정보처리기사 기출 중 빈출 문제 개념 요약
정리한 김에 올림.
자료 : 최강 자격증 기출문제 전자문제집 CBT
범위 : 2020년 06월 06일 ~ 2022년 04월 24일(8회분)
폭포수 모형 같이 몇 번 보면 외워지는 건 제외.
- 정렬 알고리즘
*8개 종류: [선택, 버블, 삽입, 쉘, 퀵, 힙, 이진병합, 버킷정렬]
*Selection Sort : 배열 내에서 최소값을 찾은 다음 정렬 되지 않은 맨 앞 값과 교환을 하며 정렬을 해 나아가는 방법 (정렬 시간 복잡도 모두 O(n^2))
*Bubble Sort : 왼쪽에서 부터 두 데이터를 비교해서 앞에 있는 데이터가 뒤에 있는 데이터 보다 크면 자리를 바꾸는 정렬 알고리즘(정렬 시간 복잡도 모두 O(n^2))
*Insert Sort : 한 개의 값을 추출한 다음 앞쪽으로 비교해서 본인의 자리를 알맞게 찾아가게끔 하는 정렬 방법. 정렬 시간 복잡도는 최상일 경우 O(n), 평균과 최악일 경우 O(n^2)
*병합 정렬 : 또한 분할 정복에 기반한 알고리즘으로 리스트를 1 이하인 상태까지 절반으로 자른 다음 재귀적으로 합병 정렬을 이용해서 전체적인 리스트를 합병하는 정렬 과정. O(n log n)
*시간 복잡도

*O(1) : 상수형 복잡도 (해시 함수)
*O(logN) : 로그형 복잡도 (이진 탐색)
*O(N) : 선형 복잡도 (순차 탐색)
*O(Nlog2N) : 선형 로그형 복잡도 (퀵 정렬, 병합정렬)
*O(N^2) : 제곱형 (거품 정렬, 삽입 정렬, 선택 정렬)
- ER 모델
*사각형 : 개체
*마름모 : 관계
*선 : 관계-속성 연결
*원형 : 속성
*겹친 타원 2개 : 다중값
- 정규화 단계
*제1정규형 : 릴레이션에 속한 모든 속성의 도메인이 원자값으로만 구성
*제2정규형 : 제1 정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속(부분 함수 종속 제거)
*제3정규형 : 제2 정규형에 속하고, 기본키가 아닌 모든 속성이 기본키에 이행적 함수 종속이 되지 않음.
*BCNF(보이스/코드) 정규형 : 릴레이션의 함수 종속 관계에서 모든 결정자가 후보키
*제4정규형 : BCNF 정규형을 만족하면서 함수 종속이 아닌 다치 종속을 제거해야 만족.
*제5정규형 : 제4 정규형을 만족하면서 후보키를 통하지 않는 조인 종속을 제거해야 만족.
- DDL, DML, DCL 차이
*DDL : Data Define Language 의 약자로, 스키마/도메인/테이블/뷰/인덱스를 정의/변경/제거할 때 사용하는 언어이다.
테이블을 생성하고, 테이블 내용을 변경하고, 테이블을 없애버리는 것.
흔히 CREATE, ALTER, DROP 을 떠올리면 된다.
*DML : Data Manipulation Language 의 약자로, Query(질의)를 통해서 저장된 데이터를 실질적으로 관리하는 데 사용한다.
테이블 안의 데이터 하나하나를 추가하고 삭제하고 수정하는 것.
흔히 INSERT, DELETE, UPDATE 를 떠올리면 된다.
*DCL : Data Control Language 의 약자로, 보안/무결성/회복/병행 제어 등을 정의하는데 사용한다. 데이터 관리 목적.
흔히 COMMIT, ROLLBACK, GRANT, REVOKE 를 떠올리면 된다.
- 스키마
* 외부스키마 : 사용자 뷰, 사용자나 개발자 관점
* 개념스키마 : 전체적인 논리적 구조
* 내부스키마 : 물리적 저장장치
-릴레이션
*(비)행기 : 행(튜플), 기수(카디널리티)
*열차 : 열(컬럼), 차수(디그리)
-트랜잭션 특징
*원자성(atomicity)
*일관성(consistency)
*격리성(isolation)
*영속성(durability)
(ACID, 산성)
- 키 정리
*기본키(Primary key)
기본키는 후보키 중에서 특별히 선정된 주키(Main Key)이며 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성이다. 기본키는 중복된 값을 가질 수 없으며 NULL값을 가질 수 없다.
*후보키(Candidate Key)
테이블에서 각 행을 유일하게 식별할 수 있는 최소한의 속성들의 집합이다. 후보키는 기본키가 될 수 있는 후보들이며 유일성과 최소성을 동시에 만족해야한다.
*대체키(Alternate Key)
대체키는 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키를 의미한다. 대체키를 보조키라고도 한다.
*슈퍼키(Super Key)
슈퍼키는 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키를 말한다. 릴레이션을 구성하는 모든 튜플 중 슈퍼키로 구성된 속성의 집합과 동일한 값은 나타내지 않는다. 슈퍼키는 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족하지만, 최소성은 만족하지 못한다.
*외래키(Foreign Key)
외래키는 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합을 의미한다. 한 릴레이션에 속한 속성 A와 참조 릴레이션의 기본키인 B가 동일한 도메인상에서 정의되었을 때의 속성 A를 외래키라고 한다. 외래키로 지정되면 참조 릴레이션의 기본키에 없는 값은 입력할 수 없다.
- 관계 해석
* ∃: 존재한다(There exist)
* ∈: t가 r에 속함( t ∈ r )
* ∀: 모든 것에 대하여(for all)
* ∪: 합집합
- IPv4와 IPv6의 차이
*IPv4
*32비트 주소
*유니캐스트/멀티캐스트/브로드캐스트 사용
*헤더 크기 : 옵션 미지정시 20바이트, 즉 최소 20바이트 이상 ~ 옵션 지정시 최대 60바이트
*IPv6
*128비트 주소
*유니캐스트, 애니캐스트, 멀티캐스트 사용
*헤더 크기 : 40바이트 고정
*기존 IPv4의 주소 부족 문제를 해결하기 개발
*인증성/기밀성/무결성 지원 (=보안성 강화)
-OSI 7계층 프로토콜
*1계층 - 물리계층(Physical Layer) : Coax, Fiber, Wireless
*2계층 - 데이터 링크계층(DataLink Layer) : Ethernet, SLIP, PPP, FDDI, HDLC
*3계층 - 네트워크 계층(Network Layer) : IP, IPSec, ICMP, IGMP, ARP, RIP, BGP
*4계층 - 전송 계층(Transport Layer) : TCP, UDP, ECN, SCTP, DCCP
*5계층 - 세션 계층(Session Layer) : NetBIOS, TLS (API, SOCKET)
*6계층 - 표현 계층(Presentation Layer) : ASCII, MPEG
*7계층 - 응용 계층(Application Layer) : HTTP, SMTP, FTP, SIP
- 기억장치 배치 전략
*First Fit: 들어갈 수 있는 첫 번째 공간에 넣음
*Best Fit: 내부 단편화(자투리)가 가장 적게 남는 공간에 넣음
*Worst Fit: 가장 큰 공간에 넣음
ex) 빈 기억공간의 크기가 20KB, 16KB, 8KB, 40KB 일 때 기억장치 배치 전략으로 “Best Fit"을 사용하여 17KB의 프로그램을 적재할 경우 내부단편화의 크기는 얼마인가?
1. 3KB
2. 23KB
3. 64KB
4. 67KB
정답 : [1]
해설 : 문제에서 Best Fit을 물을 시 내부단편화가 제일 작은 보기를 찾으면 됨
1) 20KB - 17KB = 3KB
2) 16KB - 17KB = 불가
3) 8KB - 17KB = 불가
4) 40KB - 17KB = 23KB
따라서 1번이 정답
- GoF(Gang of Four) 패턴
*GoF(Gang of Four) 패턴: 에리히 감마(Erich Gamma), 리처드 헬름(Richard Helm), 랄프 존슨(Ralph Johnson), 존 블리시데스(John Vlissides)가 같이 고안한 디자인 패턴
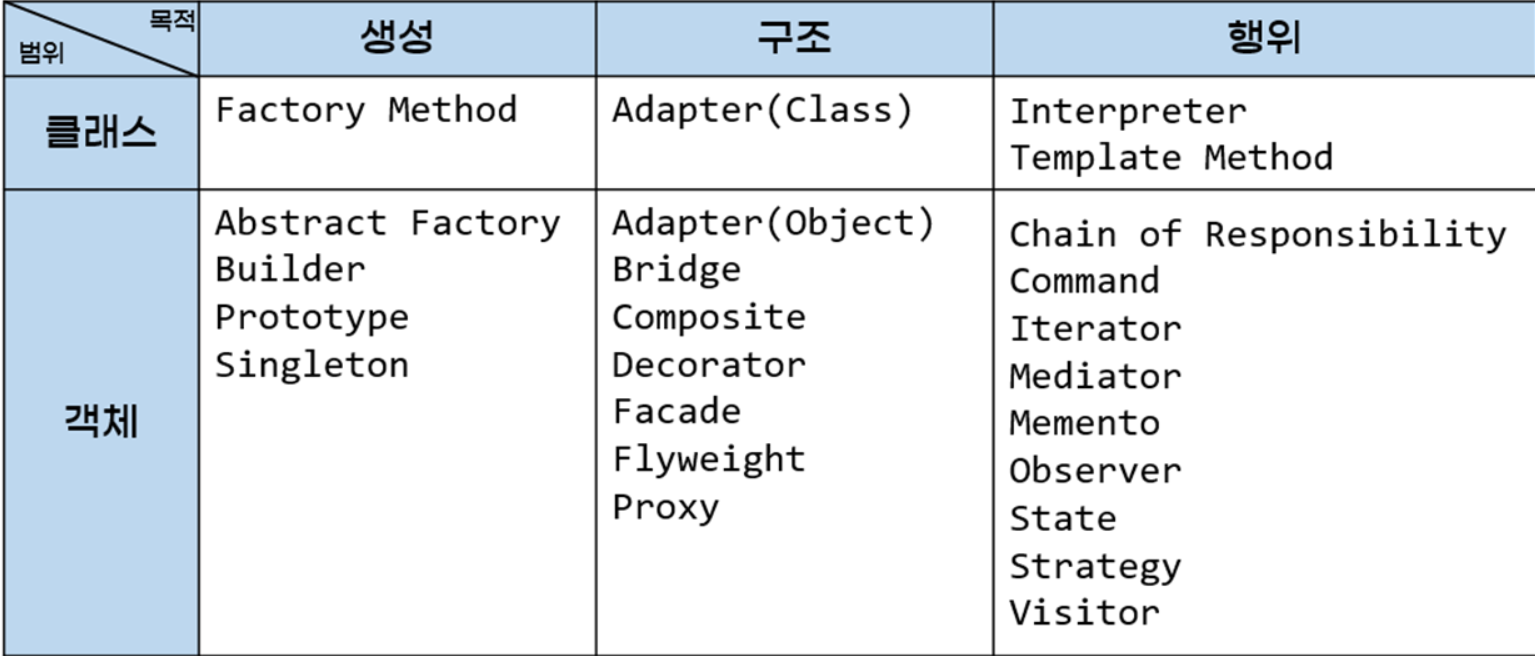
그림 출처 : https://4z7l.github.io/2020/12/25/design_pattern_GoF.html
*생성패턴 : 객체의 생성과 관련된 패턴
*구조패턴 : 클래스나 객체들을 조합하여 더 큰 구조로 만들 수 있게 해주는 패턴
*행위패턴 : 클래스나 객체들이 서로 상호작용하는 방법이나 책임 분배 방법을 정의하는 패턴
23가지 디자인 패턴을 3가지 분류로 정리한 디자인 패턴
*생성 패턴: Abstract Factory, Builder, Factory Method, Prototype, Singleton
*구조 패턴: Adapter, Bridge, Composite, Decorator, Facade, Flyweight, Proxy
*행위 패턴: Chain of Responsibility, Command, Interpreter, Iterator, Mediator, Memento, Observer, State, Strategty, Template Method, Visitor
- 객체지향 분석 방법론
*Rumbaugh : 가장 일반적으로 사용되는 방법으로 분석 활동을 객체/동적/기능 모델로 나누어 수행하는 방법
*Booch : 미시적(Micro) 개발 프로세스와 거시적(Macro) 개발 프로세스를 모두 사용하는 분석방법
*Jacobson : Use Case를 강조하여 사용하는 분석방법
*Coad와 Yourdon : E-R다이어그램을 사용하여 개체의 활동들을 데이터 모델링하는데 초점을 둔 기법
*Wirfs-Brock : 분석과 설계간의 구분이 없고 고객 명세서를 평가해서 설계 작업까지 연속적으로 수행하는 기법
- 럼바우(Rumbaugh) 분석 기법
*객체 모델링 = 객체 다이어그램
*동적 모델링 = 상태 다이어그램
*기능 모델링 = 자료 흐름도
(객2동상기자)
(다음 설명에 이 "단어"가 있으면 해당 "모델링"이 정답)
*객체 모델링 : 정보 모델링, 시스템에서 요구
*동적 모델링 : 제어, 흐름, 동작
*기능 모델링 : DFD
- 객체지향 분석 기법
1. 동적 모델링
2. 상향식
-절차지향 분석기법
1. 순차적인 처리
2. 하향식
- 단위 테스트
*하향식, 테스트 스텁
*상향식, 테스트 드라이버
- 트리 순회
*전위: Root -> Left -> Right
*중위: Left -> Root -> RIght
*후위: Left -> Right -> Root
-그래프
*McCabe의 cyclomatic 수 구하기 공식 = Edge - Node + 2
ex) Edge = 6, Node = 4 일 때, 6 - 4 + 2 = 4가 정답.
ex)

*정점이 n개인 그래프에서 최대 간선수는 n(n-1)개
*정점이 n개인 무방향 그래프에서 최대의 간선수는 n(n-1)/2개
- ip class 별 주소 범위
*A class에 속하는 ip 주소 범위: 0.0.0.0 ~ 127.255.255.255
*B class에 속하는 ip 주소 범위: 128.0.0.0 ~ 191.255.255.255
*C class에 속하는 ip 주소 범위: 192.0.0.0 ~ 223.255.255.255
*D class와 E class는 각각 멀티캐스트용, 연구용
*D class ip 주소 범위: 224.0.0.0 ~ 239.255.255.255
*E class ip 주소 범위: 240.0.0.0 ~ 255.255.255.255
A class -> B class = 128 차이
B class -> C class = 64 차이
C class -> D class = 32 차이
D class -> E class = 16 차이
- 접근 제어 방법은?
*강제접근통제(Mandatory Access Control), 주체와 객체의 등급을 비교하여 접근 권한을 부여하는 방식
*임의접근통제(Discretionary Access Control), 접근하는 사용자의 신원에 따라 접근 권한을 부여하는 방식
*사용자계정컨트롤(User Access Control), 프로그램에서 관리자 수준의 권한이 필요한 작업을 수행할 때 사용자에게 알려서 제어할 수 있도록 돕는 기능
*자료별 접근통제(Data-Label Access Control > Label-Based Access Control), 개별 행, 열에 대해 쓰기 권한, 읽기 권한을 가졌는지를 명확하게 결정하는 제어 방식
- 암호화
1.대칭키 암호화 : 암호화/복호화 키 서로 동일할 경우, 양방향
*블록 암호화 방식 : DES, SEED, AES, ARIA, IDEA
*스트림 암호화 방식 : LFSR, RC4
* 키 개수 : N(N-1)/2
2.비대칭키 암호화 : 암호화/복호화 키 서로 다를 경우, 양방향
*디피-헬만(Diffie-Hellman), RSA(소인수 분해), ECC(이산대수), Elgamal(이산대수), DSA(이산대수)
*키 개수 : 2N
3.해시 알고리즘 : 단방향
*MD5, SHA-1, SHA-256/384/512, HAS-16-, HAVAL
-DDOS 공격도구
*Trin00 : UDT flood 서비스 공격 유발
*TFN(Tribe Fleood Network) : 공격자가 공격 명령을 일련의 TFN 서버를 통해 전달, TCP, SYN Flood, ICMP Echo 요청 등의 Dos 공격
*Stacheldrht : Linux, Solaris 시스템용 멀웨어 도구
-보안관련 도구 및 방어기업
*TripWire : 백도어 탐지를 위한 리눅스 무결성 검사 탐지 도구, 디렉토리 및 DB에 생성하여 차이점 체크 및 변화 감지
*ping : 인터넷 접속 호스트가 정상 운영되고 있는지를 확인
*tcpdump : 네트워크 인터넷을 거치는 패킷 출력
*cron : 유닉스/리눅스에서 정해진 작업을 스케쥴링
*netcat : TCP/UDP 프로토콜 상 네트워크 연결에서 데이터 읽고 쓰는 프로그램
*사이버 킬 체인 : 사이버 공격에 대응하기 위한 7단계 프로세스별 공격분석
*난독화 : 코드 가독성을 낮추어 역공학에 대한 대비
*클라우드 기반 HSM(Cloud Based Hardware Security Modul) : 클라우드 기반 데이터 암호화 키 생성, 전용 하드웨어, 소프트웨어에 내재된 암호 기술 취약점 보완 가능
*허니팟(Honeypot) : 비정상적 접근 탐지
- SW 비용 추정 모형 (수학적 산정 기법)
*COCOMO 모델 : LOC( Line of Code ) 기반 비용 산정 방식
1. Embeded : 초대형 규모의 시스템 소프트웨어를 대상, 30만 라인 이상의 sw개발에 적합
2. Organic : 기관 내부의 중소 규모 sw대상, 5만 라인 이하 소프트웨어 개발에 적합
3. Semi-Detached : Organic과 Embeded의 중간 단계, 30만 라인 이하
*기능 점수 모델 : 기능 점수를 산출하여 비용 산정
*Putnam 모델 : Rayleigh-Norden 곡선의 노력 분포도를 이용한 비용 산정 기법, SLIM 사용 (SLIM : Putnam 기법 모형을 기초로 개발된 자동화 추정 도구)
(훈남(Putnam)이 노력(노력분포도)해서 슬림(SLIM)해졌네)
*Function-Point(FP) : 요구 기능을 증가시키는 인자별로 가중치를 부여 후 기능의 점수를 계산하여 비용을 산정.
- UML의 구성요소
*Things 사물
*Diagram 다이어그램
*Relationship 관계
- UML 다이어그램 종류
1. 정적(구조적) 다이어그램
*클객컴배복패 (클래스, 객체, 컴포넌트, 배치, 복합체, 패키지)
2. 동적(행위) 다이어그램
*유시커상활타상 (유스케이스, 시퀀스, 커뮤니케이션, 상태, 활동, 타이밍, 상호작용)
3. 시퀀스(Sequence) 다이어그램 : 메시지(함수호출)를 주고받으면서 시간의 흐름에 따라 상호작용하는 과정들
*액터(Actor) : 시스템으로부터 서비스를 요청하는 외부요소로, 사람이나 외부 시스템 의미
*객체(object) : 메시지를 주고받는 주체
*생명선(Lifeline) : 객체가 메모리에 존재하는 기간으로, 객체 아래쪽에 점선을 그어 표현
*메시지(Message) : 객체가 상호 작용을 위해 주고받는 메시지
*실행 상자(Active Box) : 객체가 메시지를 주고받으며 구동되고 있음을 표현
- CASE
*CASE : 시스템 개발주기의 일부 또는 전체를 자동화시킨 것
*소프트웨어 생명주기의 전체 단계를 연결해 주고 자동화해주는 통합된 도구를 제공
*소프트웨어, 하드웨어, 데이터베이스, 테스트 등을 통합하여 소프트웨어를 개발하는 환경을 제공
1.상위 CASE: 요구 분석과 설계 단계를 지원
*모델들 사이의 모순검사 기능
*모델의 오류 검증 기능
*자료흐름도 작성 기능
2.하위 CASE: 코드를 작성하고 테스트하며 문서화하는 과정 지원
*원시코드 생성 기능
- 관계 대수
1. 순수관계연산자
*select σ(시그마) ⇒수평단절, 행을 다가져옴
*project π ⇒수직단절, 열을 다가져옴
*join ▷◁ : 공통 속성을 이용해 두개의 릴레이션 튜플을연결→만들어진 튜플로 반환
*division ÷ : 릴S의 모든 튜플과 관련있는 릴R의 튜플반환
2. 일반 집합 연산자
*UNION 합집합
*INTERSECTION 교집합
*DIFFERENCE 차집합
*CARTESIAN PRODUCT 교차곱
- 결합도(Coupling)
*내용(content) > 공통(common) > 외부(external) > 제어(control) > 스템프(stamp) > 자료(data)
*뒤로 갈수록 약함
(내)(공)은 (외)(제) (쓰)(자)
- 응집도(Cohesion)
* 하나의 모듈이 하나의 기능을 수행하는 요소들간의 연관성 척도, 독립적인 모듈이 되기 위해서는 응집도가 강해야 한다.(결합도는 약해야 한다.)
*우연적(Coincidental) < 논리적(Logical) < 시간적 (Temporal) < 절차적(Procedural) < 교환적(Communication) < 순차적(Sequential) < 기능적(Functional)
*뒤로 갈수록 강함
(우)리 (논)산 (시)(절) 기억나?
(교)자랑 (순)대 (기)대했는데..
- 연산자의 우선순위
(아래로 갈수록 우선순위 낮음)
*증감 연산자( ++ -- ) → 우선 제일 순위 높음
*산술 연산자( * / % )
*산술 연산자( + - )
*시프트 연산자( << >> )
*관계 연산자(=< => < > )
*관계 연산자( == != )
*비트 연산자( & ^ | )
*논리 연산자( && ||)
*조건연산자(?:)
*대입연산자(= += *= /= %= <<= >>=)
*순서 연산자( , ) → 우선 순위 제일 낮음.
- 코드 기입 오류
*생략 오류(omission error)
입력 시 한 자리를 빼놓고 기록한 경우
(1234 → 123)
*필사 오류(Transcription error)
입력 시 임의의 한 자리를 잘못 기록한 경우
(1234 → 1235)
*전위 오류(Transposition error)
입력 시 좌우 자리를 바꾸어 기록한 경우
(1234 → 1243)
*이중 오류(Double Transposition error)
전위 오류가 두 가지 이상 발생한 경우
(1234 → 2143)
*추가 오류(Addition error)
입력 시 한 자리 추가로 기록한 경우
(1234 → 12345)
*임의 오류(Random error)
위의 오류가 두 가지 이상 결합하여 발생한 경우
(1234 → 12367)
- 디지털 저작권 관리(DRM) 기술요소
*암호화/키관리/암호화 파일생성/식별기술/저작권 표현/정책관리/크랙방지/인증
- 블랙박스 테스트의 종류
*오류 예측 검사
*동치분할검사
*경계값 분석
*비교 검사
*원인-효과 그래프 검사
(5동 경비원)
- 화이트박스 테스트의 종류
*조건 검사
*루프 검사
*데이터 흐름 검사
*기초 경로 검사
(조루 데기)
- 인수 테스트
*계약 인수 테스트(알파 테스트, 베타 테스트), 규정 인수 테스트
*알파 테스트: 개발자의 장소에서 사용자가 개발자 앞에서 행하는 테스트
*베타 테스트: 선정된 최종 사용자가 여러 명의 사용자 앞에서 행하는 테스트 기법
- IEEE 802의 표준 규약
*IEEE 802.3 : CSMA/CD
*IEEE 802.4 : Token BUS
*IEEE 802.5 : Token RING
*IEEE 802.8 : Fiber optic LANS
*IEEE 802.9 : 음성/데이터 통합 LAN
*IEEE 802.11 : 무선 LAN(CSMA/CA)
(아래부턴 안 외워도 됨)
*IEEE 802.11a - 5GHz 대역의 전파를 사용하는 규격으로, OFDM 기술을 사용해 최고 54Mbps까지의 전송 속도를 지원
*IEEE 802.11b - Wi-Fi. 11의 스루풋 확장. 11mbps
*IEEE 802.11d - 지역 간 로밍용 확장 기술
*IEEE 802.11e - QoS. MAC구현 수정. Voice over WLAN, 스트리밍을 위한 기술.
*IEEE 802.11f - 인터 엑세스 포인트 프로토콜
*IEEE 802.11g - 11b의 스루풋 확장. 54mbps
*IEEE 802.11h - DFS, TPC. 5GHz 타장비(레이다) 간섭 해결.
*IEEE 802.11i - WPA2
*IEEE 802.11j - 일본용 전송 방식
*IEEE 802.11k - 전파 자원 측정 확장 기술
*IEEE 802.11n - 40MHz대역"폭". g의 스루풋 확장. 600mbps.
*IEEE 802.11p - 빠르게 움직이는 운송 수단을 위한 무선 접속 기술
*IEEE 802.11r - 빠른 로밍
*IEEE 802.11s - ESS 메쉬 네트워킹
*IEEE 802.11t - 무선 성능 예측 (WPP)
*IEEE 802.11u - 802.11 기반이 아닌 네트워크와의 상호 연동
*IEEE 802.11v - 무선 네트워크 관리
*IEEE 802.11w - 보호된 관리 프레임
- 애자일 방법론
*소프트웨어 개발 방법에 있어서 아무런 계획이 없는 개발 방법과 계획이 지나치게 많은 개발 방법들 사이에서 타협점을 찾고자 하는 방법론/적은 규모의 개발 프로젝트에 적용하기 좋다(그중에서도 XP와 SCRUM이 제일 많이 통용)
1. XP (Extreme Programming) 의 5원칙
*용기, Courage
*단순성, Simplicity
*의사소통, Communication
*피드백, Feedback
*존중, Respect
- 소프트웨어 상위 설계
*아키텍처 설계, 데이터 설계, 시스템 분할, 인터페이스 정의, 사용자 인터페이스 설계(UI 설계)
- 소프트웨어 하위 설계
*모듈 설계, 인터페이스 작성
- 자료사전(Data Dictionary)
1. = : 자료의 정의(~로 구성되어 있다)
2. + : 자료의 연결(그리고)
3. () : 자료의 생략(생략 가능한 자료)
4. [] : 자료의 선택(또는) ex) [ A | B | C ]
5. {} : 자료의 반복
6. ** : 자료의 설명(주석)
- 정적 분석 도구
*pmd - 코드 결함 분석
*checkstyle - java코드 표준 준수 검사
*cppcheck - c/c++ 오버플로우 검사
*ccm
- 동적 분석 도구
*valance, Avalanche, Valgrind
- 인터페이스 구현 검증 도구
*xUnit : Java, C++ 등 다양한 언어 지원하는 단위 테스트 프레임워크
*STAF : 서비스 호출 및 컴포넌트 재사용 등 환경 지원하는 테스트 프레임워크
*FitNesse : 웹 기반 테스트케이스 설계, 실행, 결과 확인 등을 지원하는 테스트 프레임워크
*NTAF : FitNesse의 장점인 협업 기능과 STAF의 장점인 재사용 및 확장성을 통합한 네이버의 테스트 자동화 프레임워크이다.
*Selenium : 다양한 브라우저 및 개발 언어 지원하는 웹 애플리케이션 테스트 프레임워크
*Watir : Ruby를 사용하는 애플리케이션 테스트 프레임워크
*Ruby : 인터프리터 방식의 객체지향 스크립트 언어
- CMMI
Initial(초기) - Managed(관리) - Defined(정의) - Quantitatively Managed(잘관리된) - Optimizing(최적화)
- CMM
nitial(초기) - repeatable(반복) - Defined(정의) - Managed(관리) - Optimizing(최적화)
- 나선형 모델(소프트웨어 개발 모델) 순서
*계획 수립 → 위험 분석 → 개발 및 검증 → 고객 평가
(수분증가)
- 객체지향 설계원칙
*단일 책임 원칙(SRP, Single Responsibility Principle)
객체는 단 하나의 책임만 가져야 한다.
*개방-폐쇄의 원칙(OCP, Open Closed Principle)
기존의 코드를 변경하지 않으면서 기능을 추가할 수 있도록 설계가 되어야 한다.
*리스코프 치환 원칙(LSP, Liskov Substitution Principle)
일반화 관계에 대한 이야기며, 자식 클래스는 최소한 자신의 부모 클래스에서 가능한 행위는 수행할 수 있어야 한다.
*인터페이스 분리 원칙(ISP, Interface Segregation Principle)
인터페이스를 클라이언트에 특화되도록 분리시키라는 설계 원칙이다.
*의존 역전 원칙(DIP, Dependency Inversion Principle)
의존 관계를 맺을 때 변화하기 쉬운 것 또는 자주 변화하는 것보다는 변화하기 어려운 것, 거의 변화가 없는 것에 의존하라는 것.
- 자료 흐름도(Data Flow Diagram) 구성 요소
*프로세스 (Process) : 원
*자료 흐름(Data Flow) : 화살표
*자료 저장소(Data Store) : 평행선
*단말(Terminator) : 사각형
- 파티셔닝 유형
*파티셔닝은 병렬 데이터베이스 환경 중 수평분할에서 활용되는 분할 기법이다.
*레인지(범위) 분할
*해시 분할
*컴포지트(조합) 분할
*리스트 분할
*라운드 로빈 분할
(범해조리라)
*범위 분할(Range Partitioning) : 지정한 열의 값을 기준으로 분할
*해시 분할(Hash Partitioning) : 해시 함수를 적용한 결과 값에 따라 데이터 분할
*조합 분할(Composite Partitioning) : 범위 분할 후 해시 함수를 적용하여 다시 분할
- 공통모듈 원칙
*정확성 : 해당 기능이 실제 시스템 구현시 필요한지 아닌지를 알 수 있도록 정확하게 작성
*명확성 : 해당 기능에 대해 일관되게 이해하고 한가지로 해석될 수 있도록 작성
*완전성 : 시스템이 구현될 때 필요하고 요구되는 모든 것을 기술
*일관성 : 공통 기능 간에 상호 충돌이 없도록 작성
*추적성 : 공통 기능에 대한 요구사항 출처와 관련 시스템 등의 유기적 관계에 대한 식별이 가능하도록 작성
- DBMS(DataBase Management System) 데이터베이스 관리 시스템 고려사항 5가지
1. 가용성
2. 성능
3. 기술 지원
4. 상호 호환성
5. 구축 비용
- 소프트웨어 품질측정 개발자 관점
*무결성, 신뢰성, 사용성, 정확성, 상호 운용성, 이식성, 효율성
(무신사정상이효)
- EAI 구축 유형
*기업 내 각종 애플리케이션 및 플랫폼 간의 정보 전달 연계 통합등 상호연동이 가능하게 해주는 솔루션
*Point - to - Point : 가장 기본적인 애플리케이션 통합 방식 1:1로 연결
*Hub & Spoke : 단일 접점인 허브 시스템을 통해 데이터 전송하는 중앙 집중형 방식
*Message Bus : 애플리케이션 사이에 미들웨어를 두어 처리하는 방식
*Hybrid : Hub & Spoke 와 Message Bus 혼합 방식
- 반정규화(Denormalization) 유형 중 중복 테이블 추가 방법
*(집)계 테이블 추가 - sum,avg 등의 계산 미리 수행
*(중)복 테이블 추가 - 서버 분리 또는 업무 구별
*(이)력 테이블 추가 - 레코드 중복 저장
*(부)분 테이블 추가 - 접근 시도가 많은 자료만 모아두기
*(진)행 테이블 추가 - A에 접근하기위해 다수의 테이블을 거칠 경우 간소화
* 특정 부분만을 포함하는 테이블의 추가
- 소프트웨어 관련 법칙
*오류의 80%는 전체의 20%내에서 발견된다는 법칙 : 파레토 법칙
*지연되는 프로젝트에 인력을 더 투입하면 오히려 더 늦어진다. : Brooks의 법칙
*동일 테스트 케이스로 동일 테스트 반복 시 더 이상 결함이 발견되지 않은 현상 : 살충제 페러독스 Pesticide Paradox
*결함을 모두 제거해도 사용자 요구사항을 만족시키지 못하면 해당 소프트웨어는 품질이 높다고 말할 수 없다. : 오류 부재의 궤변
*파레토 법칙이 좌우한다. 결함은 발생한 모듈에서 계속 추가로 발생할 가능성이 높다. : 결함 집중
- 교착상태 해결 방법
1. Avoidance(회피) : 은행가 알고리즘
2. Prevention(예방)
*상호배제
*점유와대기
*환형대기
*비선점
(상점환비)
3. Detection(탐지) : 자원 할당 그래프
4. Recovery(복구) : 자원 선점/ 프로세스 종료
- 테일러링(Tailoring)
*프로젝트 상황 특성에 맞게 정의된 소프트웨어 개발 방법론 절차, 사용기법 등을 수정 및 보완하는 작업
*내부적 요건 : 납기/비용, 기술환경, 구성원 능력, 고객요구 사항
*외부적 요건 : 법적 제약사항, 국제표준 품질
- 거리 벡터 라우팅 프로토콜
*Bellman-Ford 알고리즘 사용
*RIP 프로토콜(최대 홉 수 15)
*인접 라우터와 주기적으로 정보 교환
- 링크 상태 라우팅 프로토콜
*Dijkstra 알고리즘 사용
*OSPF 프로토콜(홉 수 제한 없음)
*최단 경로, 최소 지연, 최대 처리량